一支來自史丹佛大學和 Meta 的研究團隊近日表示,Google 最新的 Gemini 模型在常識推理任務上並非落後於OpenAI的GPT模型。
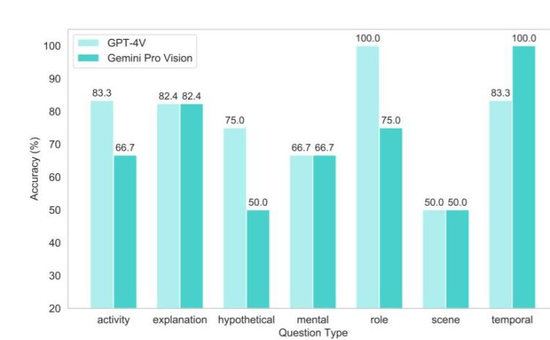
該研究團隊表示,之前基於有限數據集的評估未能完全捕捉到Gemini真正的常識推理潛力,並在新的測試集中證明Gemini的推理能力比之前強很多。
這次的評估更公平,設計了需要跨模態整合常識知識的任務,對Gemini在複雜推理任務中的表現進行深入評估。
研究團隊表示,Gemini Pro 的性能和 GPT-3.5 Pro 相當,不過在準確性上落後於 GPT-4 Turbo。
本文為品玩授權刊登,原文標題為「斯坦福大學聯手Meta,證明Gemini推理性能強於GPT-3.5」