
基於AI深度強化學習的拳擊選手身體不僅擁有超高自由度,而且它還掌握了格擋、後退、擺拳等拳擊基本動作。
Facebook人工智慧研究部門(FAIR)在機器學習領域,總能帶來一些意想不到的成果,上面的演示正是它們在《Control Strategies for Physically Simulated Characters Performing Two-player Competitive Sports》(模擬人物進行雙人競技運動的控制策略)一文中的部分演示片段。
在這篇論文中,研究人員開發了一個學習框架,通過物理模擬角色學習基本技能、學習回合級別的策略、深度強化學習的步驟方法,來模擬人們學習競技體育的訓練路線。
同時,它們還開發了一個編碼器-解碼器結構的策略模型,來讓物理模擬角色進行訓練學習,該結構包含一個自回歸潛在變量和一個專家混合解碼器。
為了展示框架的有效性,研究人員通過拳擊和擊劍兩種運動,演示了物理模擬角色在框架學習到的控制策略,這些策略可以生成戰術行為,並且讓所有動作看起來更自然。

論文概述
在雙人競技運動中,運動員經常在比賽中展示出高效的戰術動作,如拳擊和擊劍。但創建多人動畫場景是一項巨大的挑戰,因為它不僅要求每個人物模型都以自然的方式行事,而且還要求它們彼此之間的互動在時間和空間領域都是同步的,以顯得自然。
相互作用的密度越大,問題就越具有挑戰性,因為在相互作用之間沒有時間「重置」。使用物理模擬角色簡化了問題的一部分,因為低層次的物理互動(如碰撞)是通過模擬自動生成的。
然而,由於學習包含比賽的一系列技能,人們還沒有對不同技能的協調進行深入研究,如刺拳、勾拳、等拳擊級別的反擊和壓力戰鬥策略。
在競技運動中使用模擬角色的一個關鍵挑戰是,需要學習基本技能和拳擊級別的策略,以便它們能夠正確地協同工作。
在這篇論文中,FAIR探討了訓練控制系統的技術,開發了一個框架,為角色之間的互動生成控制策略。其中的人形機器人擁有超高自由度,並由關節力矩驅動。
研究人員解釋,他們的設計靈感源於現實世界。對於大多數運動來說,人們首先是在沒有對手的情況下學習基本技能,然後通過與對手競爭來學習如何結合和完善這些技能。
基於此,FAIR模仿這兩個過程,通過深度強化學習,讓物理模擬角色學習基本技能和學習比賽級別的策略。
多智慧體強化學習
如上文所述,物理模型角色不僅在前期會訓練學習基本技能,後期還會通過競技的方式來深度學習,這裡就涉及到了一個多智慧體互相學習的問題。
FAIR的框架採用一組運動數據,其中包括雙人競技運動的基本技能作為輸入,並生成兩個物理模擬選手的控制策略,控制策略允許玩家以正確的動作和時間,執行一系列基本技能,從而贏得比賽。
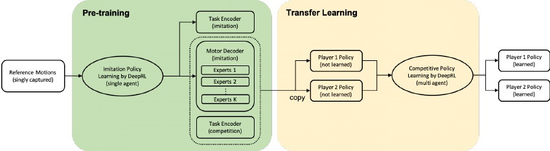
具體來看,研究人員首先會收集了一些動作數據,包括在沒有對手的情況下進行這項運動的基本技能,然後採用單智慧體深度強化學習的方法,對動作進行單一模仿策略的學習。
最後,將模仿策略轉化為競爭策略,每個參與者通過帶有競爭策略的多智慧體深度強化學習,來增強自己的策略。
為了有效地將模仿策略轉換為競爭策略,FAIR使用了一個由任務編碼器(如下圖綠色)和運動解碼器(藍色)組成的新策略模型,該任務編碼器的輸出,以自回歸的方式更新(灰色)。
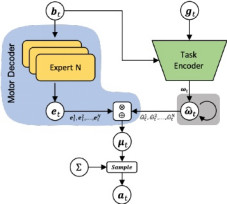
即使如此,在多智慧體環境中採用動作捕捉依然存在不少巨大的難題。當我們需要多個智慧體之間密集和豐富的交互時,由於物理交互過程中的遮擋和微妙運動,精確捕捉尤其困難。
基於此,FAIR設計一種框架,用於捕捉動作數據。首先用一個智慧體進行動作捕獲,並通過模擬和學習創建所需的競爭交互。
採用這種方法的動機,來自於人們學習競技運動的方式,新手玩家先模仿高手玩家的示範,學習基本技能,然後在與對手對戰的過程中,對所學的基本技能進行提煉和學習戰術。
小結
在這篇論文中,FAIR通過創建控制模型,使得兩個物理模擬角色進行競技運動。以拳擊和擊劍為例,儘管這種方法產生了競爭性的匹配,但這個方法仍然具有侷限性。
首先,該系統需要相當數量的計算來生成可信的競爭模型。隨著環境中涉及的變量增加,可能產生的交互也會以指數方式增加,因此所需的元組數量也以類似的方式增加。
為了使框架應用到更多運動中,如籃球或足球,更多的樣本數據是必要的。這種計算複雜性可以通過學習算法(如基於模型的RL算法)的突破來解決,或者收集更多的數據來引導智慧體之間的交互。
其次,FAIR開發的框架中有一個假設前提,即運動的個人技能可以由單個智慧體掌握,雖然該假設為角色在後期競技中的學習做了一個鋪墊,然而,在一些雙人競技運動中,這種假設並不成立。
例如,在摔跤中,一個玩家首先需要抓住另一個玩家的身體,並不斷地利用接觸來獲得分數,而這其中並不包含特別的技能需要去學習。
最後,FAIR的模型雖然能夠生成相互競爭的兩個動畫角色,但動作表現的自然程度,卻取決於輸入參考運動的品質。
例如,在拳擊比賽中,專業運動員在比賽中表現出非常敏捷的動作,而模擬的運動員卻移動得很慢。研究人員認為,造成這種差異的主要原因是實驗中使用的輸入動作,來自一個訓練非常有限的拳擊手。

雖然FAIR的這項研究並非真正成熟,仍有不少侷限性,但它發表的該篇論文具體描述了自動生成多個擁有高自由度的動畫角色模型,以及讓它們深度學習和相互競技的過程,是一篇十分具有AI前沿性質的參考文獻。
從長期來看,這個研究方向旨在提供了一種模擬的方式,讓人類能夠通過控制人工智慧進行競爭/互動,在電腦遊戲、商業電影和體育賽事中能開闢新的應用形式。
本文為雷鋒網授權刊登,原文標題為「FAIR 訓練 AI 玩拳擊,效果堪比真人比賽,試探+周旋+爆頭」