
(Isaac Gym使不同機器人在複雜環境中進行各種高性能訓練。研究人員對8種不同的複雜環境進行了基準測試,並展示了模擬器在單個GPU上進行快速策略訓練的優勢。上面:Ant, Humanoid,Franka-cube-stack,Ingenuity。下面:Shadow Hand, ANYmal, Allegro, TriFinger.)
Isaac Gym由輝達開發,通過直接將數據從物理緩存傳遞到PyTorch張量進行通訊,可以端到端地在GPU上實現物理模擬和神經網路策略訓練,無需CPU。Isaac Gym提供了一個高性能的學習平台,使得各種智慧體訓練能夠直接在GPU上進行。
與使用CPU模擬器和GPU神經網路的傳統RL訓練相比,Isaac Gym大幅度縮減了複雜機器任務在單個GPU上的訓練時間,使其訓練速度提高了1到2個數量級。
簡介
近年來,強化學習(RL)已經成為機器學習中最值得研究的領域之一,它在解決複雜決策問題方面擁有巨大的潛力。無論是圍棋、國際象棋等經典策略遊戲,還是《星際爭霸》、《DOTA》等即時戰略遊戲,深度強化學習(Deep RL)對於這種具有挑戰性的任務表現得都很突出,它在機器人環境中的表現也令人印象深刻,包括腿部運動和靈巧的操作等。
模擬器可以提高學習過程中的安全性和迭代速度,在訓練機器人的過程中發揮著關鍵作用。在真實世界中訓練仿人機器人,比如讓它進行上下樓梯的訓練,可能會破壞其器械和周邊環境,甚至有可能傷害到操控它的研究人員,有一種方法可以排除在現實世界中訓練的安全隱患,那就是在模擬器內進行訓練。
模擬器可以提供一個高效、可擴展的平台,允許進行大量試錯實驗。目前,大多數研究人員還是結合CPU和GPU來運行強化學習系統,利用這兩個部分,分別處理物理模擬和渲染過程的不同步驟。CPU用於模擬環境物理、計算獎勵和運行環境,而GPU則用於在訓練和推理過程中加速神經網路模型,以及在必要時進行渲染。
然而,在優化順序任務的CPU內核和提供大規模並行性的GPU之間來回轉換,需要在訓練中系統的不同部分的多個點之間傳輸數據,這種做法從本質上來說是非常低效的。因此,機器人深度強化學習的擴展面臨著兩個關鍵瓶頸:(1)龐大的計算需求、(2)模擬速度有限。機器人在進行高度自由的複雜學習行為時,這些問題尤為突出。
物理引擎如MuJoCo、PyBullet、DART、Drake、V-Rep等都需要大型CPU集群來解決具有挑戰性的RL任務,這些無一不面臨著上述瓶頸。例如,在「Solving Rubik’s Cube with a Robot Hand」這項研究中,近30,000個CPU核心(920台工人機器,每台有32個核心)被用來訓練機器人使用RL解決魔方任務。在一個類似研究「Learning dexterous in-hand manipulation」中,使用了一個由384個系統組成的集群,包含6144個CPU核,加上8個NVIDIA V100 GPU,進行30個小時的訓練,RL才能收斂。
用硬體加速器可以加快模擬和訓練。在電腦圖形學方面已經取得巨大成功的GPU自然也能適用於高度並行的模擬。「Gpu-accelerated robotic simulation for distributed reinforcement learning」研究中採取了這種方法,並顯示了在GPU上運行模擬的令人喜出望外的結果,這證明了有可能可以極大縮減訓練時間,以及使用RL解決極具挑戰性的任務所需的計算資源。
但是,此項工作中仍有一些瓶頸沒有解決,模擬是在GPU上進行的,但物理狀態會被複製回CPU。因此,觀察和獎勵是用優化的C++程式碼計算的,接著再複製回GPU,在那裡運行策略和價值網路。此外,該項工作只訓練了簡單的基於物理學的場景,而不是具有代表性的機器人環境,也沒有嘗試實現sim2real(從模擬環境遷移到現實環境)。
為了解決這些瓶頸問題,我們提出了Isaac Gym,一個端到端的高性能機器人模擬平台。它可以運行一個端到端的GPU加速訓練管道,使研究人員能夠克服上述限制,在連續控制任務中實現100倍~1000倍的訓練速度。
Isaac Gym利用NVIDIA PhysX提供了一個GPU加速的模擬後端,使其能夠以使用高度並行才能實現的速度,來收集機器人RL所需的經驗數據。它提供了一個基於PyTorch張量的API,來訪問GPU上的物理模擬結果。觀察張量可以作為策略網路的輸入,產生的行動張量可以直接回饋給物理系統。我們注意到,其他研究人員最近已經開始嘗試使用與Isaac Gym類似的方法,在硬體加速器上運行端到端訓練。
通過端到端方法,包括觀察、獎勵和動作緩存的整個學習過程,可以直接在GPU上進行,無需從CPU上讀回數據。這種設置允數以萬計的模擬環境在一個GPU上同時進行,使研究人員能夠只使用一個小型GPU伺服器就能解決以前無法完成的任務,輕鬆地在桌上型電腦上運行以前需要在整個數據中心才能進行的實驗。
Isaac Gym為創建和填充機器人及物體的場景提供了一個簡單的API,支持從常見的URDF和MJCF文件格式加載數據。每個環境可根據需要被複製多次,並且同時保留了副本的可變性(例如通過Domain Randomization來合成新數據)。在不與其他環境互動的情況下,這些環境可以同時進行模擬。而且,研究人員用一個完全由GPU加速的模擬和訓練管道降低了研究的門檻,使其可以用一個GPU解決以前只能在大規模CPU集群上實現的任務。
Isaac Gym還包括一個基本的近似策略優化(PPO)執行和一個簡單的RL任務系統,用戶可以根據需要替換其他任務系統或RL算法。雖然一些研究使用PyTorch,但用戶也應該能夠通過進一步的訂製與TensorFlow訓練庫整合。

(圖2:Isaac Gym管道的圖示。Tensor API為Python程式碼提供了一個接口,可以直接在GPU上啓動PhysX後端,獲取和設置模擬器狀態,從而使整個RL訓練管道的速度提高100-1000倍,同時提供高保真模擬和與現有機器人模型連接的能力。)
表徵模擬性能
研究人員首先將模擬性能描述為環境數量的函數。當改變這個數字時,目的是通過按比例減少horizon length(即PPO的步驟數,計算獎勵前智慧體的執行步驟數)來保持RL智慧體觀察到的整體經驗不變,以便進行公平的比較。雖然我們在後面提供了許多環境的詳細訓練研究,但這裡只描述了Ant、Humanoid 和Shadow Hand的模擬性能,因為它們足夠複雜,可以測試模擬的極限,也代表了複雜性的逐步增加。這三種環境都使用前饋網路進行訓練。
螞蟻:
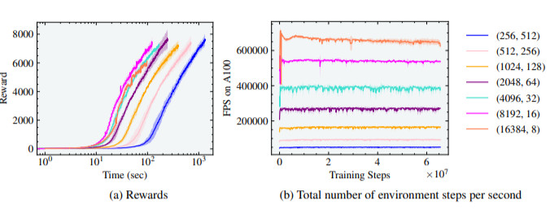
(圖3:螞蟻實驗的獎勵和有效FPS與並行環境的數量有關,最佳訓練時間是在8192個環境和16個horizon length的情況下實現的。)
研究人員首先用標準的螞蟻環境進行實驗,在這個環境中,訓練智慧體在平地上運動。我們發現,隨著智慧體數量的增加,訓練時間如預期的那樣減少了,也就是當把環境的數量從256個增加為8192個(增加了5個數量級)後,使得達到7000獎勵的訓練時間減少了一個數量級,訓練時間從1000秒(約16.6分鐘)減少到100秒(約1.6分鐘)。然而,請注意,螞蟻在單個GPU上僅用20秒就達到了3000獎勵的高性能運動。
由於螞蟻是最簡單的模擬環境之一,如圖3(b)所示,每秒並行環境步驟的數量可高達700K。由於horizon length減少,當環境數量從8192增加到16384時,沒有觀察到收益。
人形物體(Humanoid):

仿人環境有更多的自由度,需要智慧體發現用兩隻腳保持平衡並在地面上行走的步態。從圖4和圖5可以看出,與圖3中的螞蟻相比,訓練時間增加了一個數量級。

(圖4:人形實驗的獎勵和有效FPS與並行環境的數量有關,最佳訓練時間是在4096個環境和32個horizon length 的情況下實現的。)

(圖5:人形實驗的獎勵和有效FPS與平行環境的數量有關,在4096和8192個環境中實現了最佳訓練時間,horizon length 分別為64和32。)
研究人員在圖中4還注意到,隨著智慧體數量的增加,從256個增加到4096個,達到最高獎勵7000的訓練時間從10^4秒(約2.7小時)減少到10^3秒(約17分鐘)的數量級。然而,獎勵為5000左右時,高性能運動出現了,訓練時間僅為4分鐘。在這種情況下,如果超過4096個環境,就不會有進一步的收益,實際上會導致訓練時間的增加和收斂於次優步態。研究人員將此歸因於環境的複雜性,這使得在如此小的horizon length 上學習行走具有挑戰性。
可以通過對另一組環境和horizon length的組合,進行訓練來驗證這一點,與圖4相比,horizon length增加了2倍。如圖5所示,即使在8192和16384環境中,人形機器人也能行走,這兩個環境的horizon length 分別為32和16,但足夠長,可以進行學習。
另外值得注意的是,由於自由度的增加,每秒並行環境步驟的數量從螞蟻的700K減少到人形的200K,如圖4和5所示。
影子手( Shadow Hand):


(圖6:Shadow Hand實驗的獎勵和有效FPS與並行環境的數量有關,在8192和16384個環境以及16和8個horizon length 的情況下,達到最佳訓練時間。)
最後,研究人員用影子手進行實驗,讓它學習用手指和手腕將放在手掌上的立方體旋轉到目標方向。受所涉及的DoF數量和旋轉過程中的接觸影響,這項任務具有不小的挑戰。我們在「影子手」環境中的結果也遵循類似的趨勢。隨著智慧體數量的增加,在這種情況下,從256增加到16384,訓練時間減少了一個數量級,從5×10^4秒(約14小時)到3×10^3秒(約1小時)。我們發現,該環境在短短5分鐘內就達到了連續10次成功的獎勵的靈巧性能。此外,16384個智能體的horizon length為8,仍然允許學習重新擺放立方體,16384個智慧體的最大有效幀率為每秒150K個並行環境步驟。

(圖7:運動環境和相應的獎勵曲線)
研究表明,Isaac Gym是一個高性能和高仿真的平台,可以在單個NVIDIA A100 GPU上對許多具有挑戰性的模擬機器人環境進行快速訓練,而以前使用傳統的RL設置和純CPU的模擬器,則需要大型異構集群的CPU和GPU。此外,模擬後端也適用於學習具有接觸的操作,這一點在我們用ANYmal運動和TriFinger立方體擺放進行的模擬到真實的遷移演示中,得到了證實。
本文為雷鋒網授權刊登,原文標題為「告別CPU,加速100-1000倍!只用GPU就能完成物理模擬和強化學習訓練」